99 KiB
Pivot Tables¶
Pivoting data can sometimes help clarify relationships and connections.
Full documentation on a variety of related pivot methods: https://pandas.pydata.org/docs/user_guide/reshaping.html
Data¶
import numpy as np
import pandas as pd
df = pd.read_csv('Sales_Funnel_CRM.csv')
df
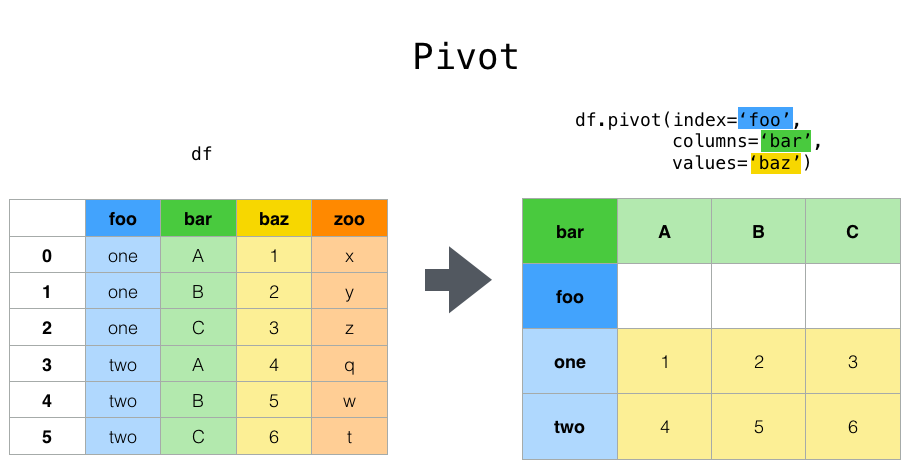
The pivot() method¶
The pivot method reshapes data based on column values and reassignment of the index. Keep in mind, it doesn't always make sense to pivot data. In our machine learning lessons, we will see that our data doesn't need to be pivoted. Pivot methods are mainly for data analysis,visualization, and exploration.
Here is an image showing the idea behind a pivot() call:
help(pd.pivot)
Note: Common Point of Confusion: Students often just randomly pass in index,column, and value choices in an attempt to see the changes. This often just leads to formatting errors. You should first go through this checklist BEFORE running a pivot():¶
- What question are you trying to answer?
- What would a dataframe that answers the question look like? Does it need a pivot()
- What you want the resulting pivot to look like? Do you need all the original columns?
df
** What type of question does a pivot help answer?**
Imagine we wanted to know, how many licenses of each product type did Google purchase? Currently the way the data is formatted is hard to read. Let's pivot it so this is clearer, we will take a subset of the data for the question at hand.
# Let's take a subset, otherwise we'll get an error due to duplicate rows and data
licenses = df[['Company','Product','Licenses']]
licenses
pd.pivot(data=licenses,index='Company',columns='Product',values='Licenses')
The pivot_table() method¶
Similar to the pivot() method, the pivot_table() can add aggregation functions to a pivot call.
df
# Notice Account Number sum() doesn't make sense to keep/use
pd.pivot_table(df,index="Company",aggfunc='sum')
# Either grab the columns
pd.pivot_table(df,index="Company",aggfunc='sum')[['Licenses','Sale Price']]
# Or state them as wanted values
pd.pivot_table(df,index="Company",aggfunc='sum',values=['Licenses','Sale Price'])
df.groupby('Company').sum()[['Licenses','Sale Price']]
pd.pivot_table(df,index=["Account Manager","Contact"],values=['Sale Price'],aggfunc='sum')
Columns are optional - they provide an additional way to segment the actual values you care about. The aggregation functions are applied to the values you list.
pd.pivot_table(df,index=["Account Manager","Contact"],values=["Sale Price"],columns=["Product"],aggfunc=[np.sum])
pd.pivot_table(df,index=["Account Manager","Contact"],values=["Sale Price"],columns=["Product"],aggfunc=[np.sum],fill_value=0)
# Can add multiple agg functions
pd.pivot_table(df,index=["Account Manager","Contact"],values=["Sale Price"],columns=["Product"],
aggfunc=[np.sum,np.mean],fill_value=0)
# Can add on multiple columns
pd.pivot_table(df,index=["Account Manager","Contact"],values=["Sale Price","Licenses"],columns=["Product"],
aggfunc=[np.sum],fill_value=0)
# Can add on multiple columns
pd.pivot_table(df,index=["Account Manager","Contact","Product"],values=["Sale Price","Licenses"],
aggfunc=[np.sum],fill_value=0)
# get Final "ALL" with margins = True
# Can add on multiple columns
pd.pivot_table(df,index=["Account Manager","Contact","Product"],values=["Sale Price","Licenses"],
aggfunc=[np.sum],fill_value=0,margins=True)
pd.pivot_table(df,index=["Account Manager","Status"],values=["Sale Price"],
aggfunc=[np.sum],fill_value=0,margins=True)